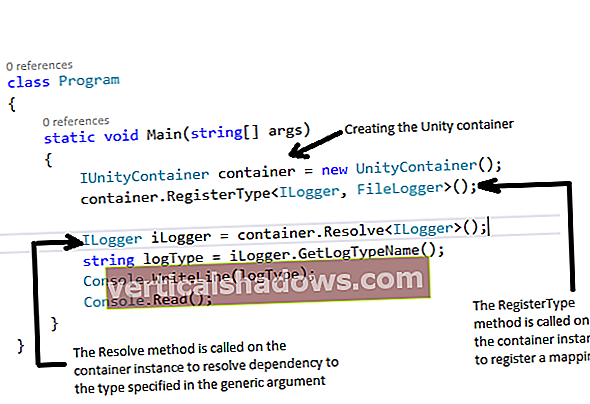
Ko sem iskal JavaWorldSpletno mesto za ideje za ta mesec Korak za korakom, Naletel sem le na nekaj člankov, ki zajemajo dostop do datotek na nizki ravni. Čeprav nam API-ji na visoki ravni, kot je JDBC, omogočajo prilagodljivost in moč, potrebne za velike poslovne aplikacije, mnogi manjši programi zahtevajo bolj preprosto in elegantno rešitev.
V tem članku bomo zgradili razširitev RandomAccessFile razred, ki nam omogoča shranjevanje in pridobivanje zapisov. Ta "datoteka zapisov" bo enakovredna trajni zgoščevalni tabeli, ki omogoča shranjevanje in pridobivanje predmetov s ključem iz pomnilnika datotek.
Uvodnik o datotekah in zapisih
Preden skočimo brezglavo v primer, začnimo z osnovnim ozadjem. Začeli bomo z opredelitvijo nekaterih izrazov, ki se nanašajo na datoteke in zapise, nato bomo na kratko razpravljali o predavanju java.io.RandomAccessFile in odvisnost od platforme.
Terminologija
Naslednje opredelitve so prilagojene našemu primeru in ne tradicionalni terminologiji baz podatkov.
Snemaj - Zbirka povezanih podatkov, shranjenih v datoteki. Zapis ima običajno več polja, od katerih je vsak poimenovan in vtipkan podatek.
Ključ - identifikator zapisa. Tipke so ponavadi unikatne.
mapa - zaporedno zbiranje podatkov, shranjenih v nekakšnem stabilnem pomnilniku, kot je trdi disk.
Neposreden dostop do datotek - Omogoča branje podatkov s poljubnih mest v datoteki.
Kazalec datoteke - Številka, ki ima položaj naslednjega bajta podatkov, ki ga je treba prebrati iz datoteke.
Kazalec za snemanje - Kazalec zapisa je kazalec datoteke, ki kaže na mesto, kjer se določen zapis začne.
Kazalo - sekundarno sredstvo za dostop do zapisov v datoteki; to pomeni, da preslika ključe za snemanje kazalcev.
Kup - Zaporedna datoteka neurejenih in spremenljivo velikih zapisov. Kup potrebuje nekaj zunanjega indeksiranja, da lahko smiselno dostopa do zapisov.
Vztrajnost - Nanaša se na shranjevanje predmeta ali zapisa za določen čas. Ta čas je običajno daljši od razpona enega procesa, zato so predmeti običajno vztrajala v datotekah ali zbirkah podatkov.
Pregled razreda java.io.RandomAccessFile
Razred RandomAccessFile je Javin način zagotavljanja neposlednega dostopa do datotek. Razred nam omogoča skok na določeno mesto v datoteki z uporabo iskati () metoda. Ko je kazalec datoteke nameščen, je mogoče podatke brati in zapisovati v datoteko s pomočjo DataInput in DataOutput vmesniki. Ti vmesniki nam omogočajo branje in pisanje podatkov na način, neodvisen od platforme. Druge priročne metode v RandomAccessFile nam omogočajo, da preverimo in nastavimo dolžino datoteke.
Premisleki, odvisni od platforme
Sodobne zbirke podatkov se zanašajo na diskovne pogone. Podatki na diskovnem pogonu so shranjeni v bloki, ki so razporejene po skladbe in površine. Diski iščite čas in rotacijska zakasnitev narekujejo, kako lahko podatke najučinkoviteje shranjujemo in pridobivamo. Tipičen sistem za upravljanje baz podatkov se za poenostavitev delovanja zanaša na atribute diska. Na žalost (ali na srečo, odvisno od vašega zanimanja za I / O datoteke na nizki ravni!), Ti parametri pri uporabi visokokakovostnega API-ja datotek niso dosegljivi java.io. Glede na to dejstvo naš primer ne bo upošteval optimizacij, ki bi jih lahko zagotovilo poznavanje parametrov diska.
Oblikovanje primera RecordsFile
Zdaj smo pripravljeni oblikovati svoj primer. Za začetek bom predstavil nekaj načrtovalnih zahtev in ciljev, odpravil težave s sočasnim dostopom in določil format datoteke na nizki ravni. Preden nadaljujemo z izvedbo, si bomo ogledali tudi glavne operacije zapisov in njihove ustrezne algoritme.
Zahteve in cilji
Naš glavni cilj v tem primeru je uporaba a RandomAccessFile zagotoviti način shranjevanja in pridobivanja podatkov o zapisu. Povezali bomo tip tipa Vrvica z vsakim zapisom kot sredstvom za njegovo enolično identifikacijo. Tipke bodo omejene na največjo dolžino, čeprav podatki o zapisu ne bodo omejeni. Za namene tega primera bodo naši zapisi sestavljeni iz samo enega polja - "bloba" binarnih podatkov. Koda datoteke ne bo poskušala na kakršen koli način razlagati podatkov zapisa.
Kot drugi cilj oblikovanja bomo zahtevali, da število zapisov, ki jih podpira naša datoteka, ni določeno v času ustvarjanja. Datoteki bomo omogočili, da raste in se skrči, ko bodo zapisi vstavljeni in odstranjeni. Ker bodo naši podatki o indeksu in zapisu shranjeni v isti datoteki, bomo zaradi te omejitve dodali dodatno logiko za dinamično povečanje prostora indeksa z reorganizacijo zapisov.
Dostop do podatkov v datoteki je veliko zaporednejši kot dostop do podatkov v pomnilniku. To pomeni, da bo število dostopov do datotek, ki jih opravi baza podatkov, odločilni dejavnik učinkovitosti. Zahtevali bomo, da naše glavne operacije z bazo podatkov niso odvisne od števila zapisov v datoteki. Z drugimi besedami, bodo stalnega časa naročila glede dostopov do datotek.
Kot zadnjo zahtevo bomo domnevali, da je naš indeks dovolj majhen za nalaganje v pomnilnik. Tako bomo lažje izpolnili zahtevo, ki narekuje čas dostopa. Kazalo bomo zrcalili v Hashtable, ki zagotavlja takojšnja iskanja v glavi zapisa.
Popravek kode
Koda tega članka vsebuje napako, zaradi katere v mnogih možnih primerih vrže NullPointerException. V abstraktnem razredu BaseRecordsFile je rutina z imenom insureIndexSpace (int). Koda je namenjena premikanju obstoječih zapisov na konec datoteke, če je treba območje indeksa razširiti. Ko se kapaciteta prvega zapisa ponastavi na dejansko velikost, se premakne na konec. DataStartPtr je nato nastavljen tako, da kaže na drugi zapis v datoteki. Na žalost, če je bilo v prvem zapisu prostega prostora, novi dataStartPtr ne bo kazal na veljaven zapis, saj je bil povečan za prvi zapis dolžina in ne njegova zmogljivost. Spremenjeni vir Java za BaseRecordsFile je na voljo v virih.
od Rona Walkupa
Višji programski inženir
bioMerieux, Inc.
Sinhronizacija in sočasen dostop do datotek
Za poenostavitev začnemo s podporo samo enonitnemu modelu, pri katerem je prepovedano istočasno izvajati zahteve za datoteke. To lahko dosežemo s sinhronizacijo metod javnega dostopa BaseRecordsFile in RecordsFile razredih. Upoštevajte, da lahko to omejitev sprostite, če želite dodati podporo za sočasno branje in pisanje v nespornih zapisih: vzdrževati boste morali seznam zaklenjenih zapisov in prepletati branje in pisanje za sočasne zahteve.
Podrobnosti o obliki datoteke
Zdaj bomo izrecno opredelili obliko zapisa datoteke. Datoteka je sestavljena iz treh regij, vsaka s svojo obliko.
Območje naslovov datotek. V tej prvi regiji sta dve glavni glavi, potrebni za dostop do zapisov v naši datoteki. Prva glava, imenovana kazalec za zagon podatkov, je dolga ki kaže na začetek zapisa. Ta vrednost nam pove velikost indeksne regije. Druga glava, imenovana glava num zapisov, je int ki podaja število zapisov v zbirki podatkov. Območje glav se začne s prvim bajtom datoteke in se razteza za FILE_HEADERS_REGION_LENGTH bajtov. Uporabili bomo readLong () in readInt () prebrati glave in writeLong () in writeInt () da napišem glave.
Indeksno območje. Vsak vnos v indeksu je sestavljen iz ključa in glave zapisa. Indeks se začne v prvem bajtu za območjem glav datotek in se razširi do bajta pred kazalcem zagona podatkov. Iz teh informacij lahko izračunamo kazalec datoteke na začetek katerega koli od n vnose v indeks. Vnosi imajo fiksno dolžino - ključni podatki se začnejo v prvem bajtu v indeksnem vnosu in se razširijo MAX_KEY_LENGTH bajtov. Ustrezni naslov zapisa za dani ključ sledi takoj za ključem v indeksu. Glava zapisa nam pove, kje se podatki nahajajo, koliko bajtov lahko vsebuje zapis in koliko bajtov dejansko vsebuje. Vnosi indeksa v indeksu datoteke niso v določenem vrstnem redu in ne ustrezajo vrstnemu redu, v katerem so zapisi shranjeni v datoteki.
Zapišite podatkovno območje. Podatkovno območje zapisa se začne na mestu, ki ga kaže kazalnik za zagon podatkov, in se razteza do konca datoteke. Zapisi se v datoteki namestijo drug proti drugemu, pri čemer med zapisi ni dovoljen prost prostor. Ta del datoteke je sestavljen iz surovih podatkov brez glave ali ključnih informacij. Datoteka zbirke podatkov se konča v zadnjem bloku zadnjega zapisa v datoteki, zato na koncu datoteke ni dodatnega prostora. Datoteka raste in se zmanjšuje, ko se zapisi dodajajo in brišejo.
Velikost, dodeljena zapisu, ne ustreza vedno dejanski količini podatkov, ki jih zapis vsebuje. Zapis si lahko predstavljamo kot posodo - morda je le delno poln. Veljavni podatki o zapisu so nameščeni na začetku zapisa.
Podprte operacije in njihovi algoritmi
The RecordsFile bo podpiral naslednje glavne operacije:
Vstavi - datoteki doda nov zapis
Preberi - prebere zapis iz datoteke
Posodobi - posodobi zapis
Delete - izbriše zapis
Zagotovite zmogljivost - Prirašča indeksno območje, da bo lahko zajemalo nove evidence
Preden stopimo skozi izvorno kodo, si oglejmo izbrane algoritme za vsako od teh operacij:
Vstavi. Ta operacija v datoteko vstavi nov zapis. Za vstavljanje smo:
- Prepričajte se, da vstavljeni ključ že ni v datoteki
- Zagotovite, da je območje indeksa dovolj veliko za dodaten vnos
- V datoteki poiščite dovolj prostora za zapis
- Zapišite podatke o zapisu v datoteko
- V indeks dodajte glavo zapisa
Preberite. Ta operacija pridobi datoteko na podlagi ključa iz datoteke. Za pridobitev zapisa:
- Z indeksom preslikajte dani ključ na glavo zapisa
- Poiščite do začetka podatkov (s kazalcem na podatke o zapisu, shranjene v glavi)
- Preberite podatke zapisa iz datoteke
Nadgradnja. Ta operacija posodobi obstoječi zapis z novimi podatki in nadomesti nove podatke s starimi. Koraki za posodobitev se razlikujejo glede na velikost novih podatkov o zapisu. Če se novi podatki prilegajo obstoječemu zapisu, bomo:
- Podatke zapisa zapišite v datoteko, tako da prepišete prejšnje podatke
- Posodobite atribut, ki vsebuje dolžino podatkov v glavi zapisa
V nasprotnem primeru, če so podatki preveliki za zapis, bomo:
- Izvedite operacijo brisanja obstoječega zapisa
- Izvedite vstavljanje novih podatkov
Izbriši. Ta operacija odstrani zapis iz datoteke. Za izbris zapisa:
Izkoristite prostor, dodeljen zapisu, ki ga odstranite, tako da skrčite datoteko, če je zapis zadnji v datoteki, ali tako, da dodate njen prostor sosednjemu zapisu
- Odstranite glavo zapisa iz indeksa tako, da vnos, ki ga izbrišete, nadomestite z zadnjim vnosom v indeksu; to zagotavlja, da je indeks vedno poln, brez praznih presledkov med vnosi
Zagotovite zmogljivost. Ta operacija zagotavlja, da je območje indeksa dovolj veliko, da lahko sprejme dodatne vnose. V zanki premikamo zapise od spredaj do konca datoteke, dokler ni dovolj prostora. Če želite premakniti en zapis:
Poiščite glavo zapisa prvega zapisa v datoteki; Upoštevajte, da je to zapis s podatki na vrhu področja podatkov o zapisu - ne zapis s prvo glavo v indeksu
Preberite podatke ciljnega zapisa
Datoteko povečajte glede na velikost podatkov ciljnega zapisa s pomočjo
setLength (dolga)metoda vRandomAccessFilePodatke o zapisu zapišite na dno datoteke
Posodobite kazalnik podatkov v zapisu, ki je bil premaknjen
- Posodobite globalno glavo, ki kaže na podatke prvega zapisa
Podrobnosti o izvedbi - korak skozi izvorno kodo
Zdaj smo pripravljeni umazati roke in predelati kodo za primer. Celoten vir lahko prenesete iz virov.
Opomba: Za prevajanje vira morate uporabiti platformo Java 2 (prej JDK 1.2).
Razred BaseRecordsFile
BaseRecordsFile je abstraktni razred in je glavna izvedba našega primera. Opredeljuje glavne metode dostopa ter množico uporabnih metod za manipulacijo zapisov in vnosov indeksa.